
Influence-Salient Coordination Shaping for Scalable Cooperative MARL
Influence-Salient Coordination Shaping (ISCS) is a research project on cooperative multi-agent reinforcement learning (MARL), focused on helping learning-based agents develop stronger interaction-driven coordination. In many cooperative tasks, agents must do more than independently maximize a shared reward: they need to create opportunities for teammates, respond to each other’s actions, and stabilize useful coordination patterns over time.
This work was accepted as:
Sheng, W., & Paleja, R. (2026). “Influence-Salient Coordination Shaping for Scalable Cooperative MARL.” In Proceedings of the ICLR Workshop on AI for Mechanism Design and Strategic Decision Making (AIMS).
and also be presented at the Purdue Computer Science Graduate Symposium.
Motivation
Cooperative MARL often struggles to induce robust teamwork, especially as the number of agents increases. Even when all agents share the same team reward, decentralized learning and weak credit assignment can lead to brittle or loosely coupled behaviors. This issue becomes especially clear in coordination-heavy Overcooked-AI layouts, where strong performance requires agents to stage resources, pass objects, specialize roles, and time complementary actions.
A core motivation of this project is that sparse team reward alone may not be enough to teach agents which actions create useful opportunities for teammates. For example, in a multi-agent kitchen environment, placing an object on a counter may only become valuable if another agent later picks it up and continues the task. ISCS is designed to make this kind of delayed teammate response more learnable.
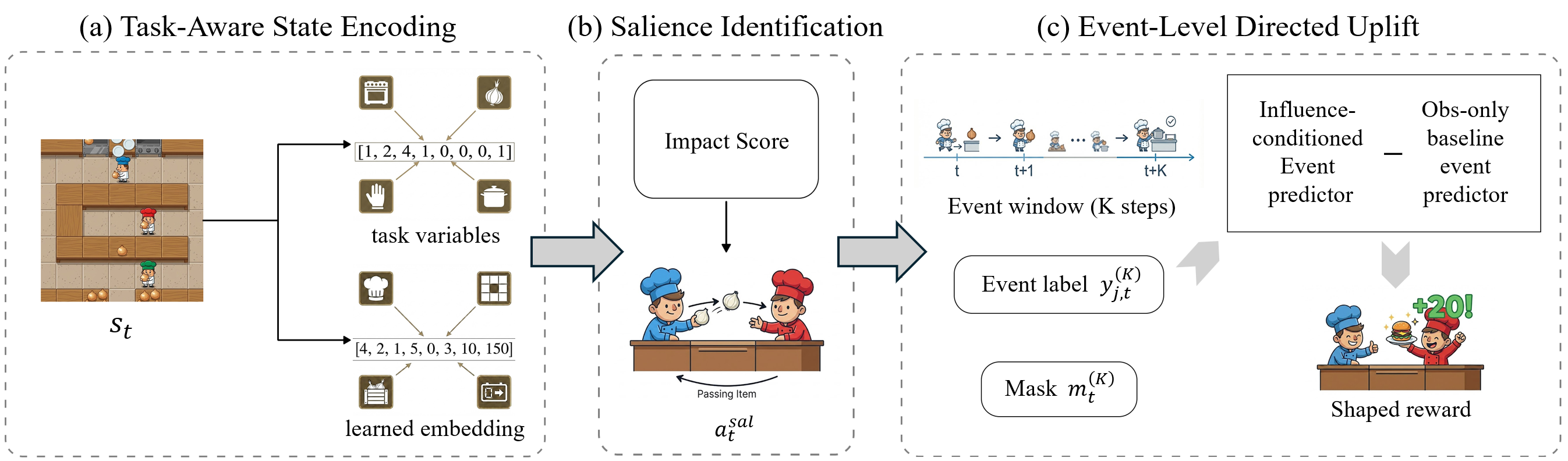
Method Overview
ISCS introduces an intrinsic shaping signal that rewards actions predicted to increase the likelihood of useful teammate follow-up behavior. The method first identifies influence-salient actions by measuring how much an agent’s action is expected to change a task-aware representation of the joint state. These salient choices often correspond to actions that create coordination opportunities, such as staging an object, initiating a handoff, or enabling a teammate’s next step.
The second component is a directed, baseline-adjusted uplift bonus. For each ordered pair of agents, ISCS compares two predictions: an influence-conditioned predictor that estimates a teammate’s short-horizon response given the source agent’s action, and an observation-only baseline that estimates the same response from the joint observation alone. The difference between these predictions measures whether the source agent’s action increases the probability of a teammate’s coordination event beyond what the state already explains.
To reduce timing sensitivity, ISCS uses an event-level K-step formulation instead of requiring an immediate next-step reaction. This allows the method to reward actions whose coordination effects appear after a short delay, such as when a teammate needs several steps to move into position before responding.
Experimental Evaluation
We evaluated ISCS in scalable Overcooked-AI environments with 2, 3, and 4 agents. The experiments compared ISCS as an additive shaping mechanism on top of standard centralized-training decentralized-execution MARL backbones, including MAPPO and HAPPO. The evaluation included layouts designed to test different coordination challenges, such as passing-beneficial layouts and congestion-heavy layouts.
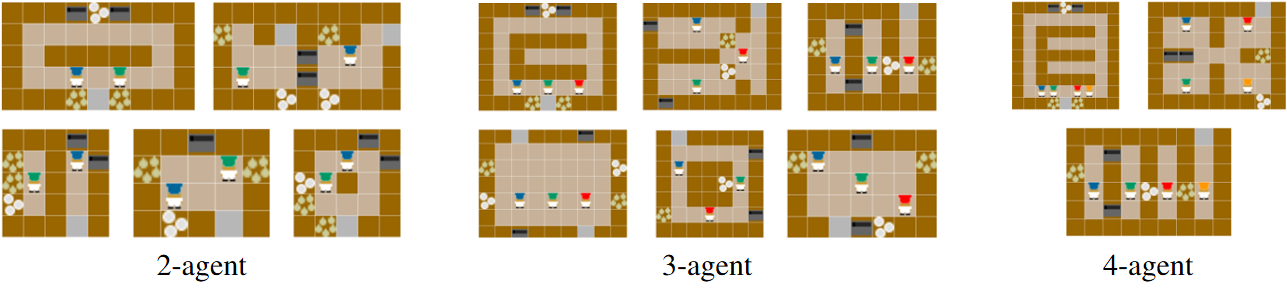
Across representative layouts, ISCS improved both sample efficiency and final task performance. The strongest gains appeared in settings where interaction-driven behavior was most important. In the Pipeline layout, for example, MAPPO+ISCS substantially improved over MAPPO, with the largest reported gain appearing in the 3-agent setting. Behavioral analysis also showed that ISCS increased counter-mediated handoffs and promoted stronger role differentiation within the team.
Project Outcome
This project introduced ISCS as a scalable shaping mechanism for cooperative MARL. Instead of only optimizing sparse shared reward, ISCS gives agents a more targeted learning signal for actions that induce useful teammate responses. The results suggest that directed, short-horizon influence modeling can help agents discover stronger coordination behaviors, particularly in larger teams where credit assignment and delayed responses make cooperation harder to learn.
This work also served as a foundation for my broader research direction on human-AI collaboration, human-machine teaming, and coordination-oriented multi-agent learning.